Germany
Breadcrumb navigation
SX-Aurora TSUBASA Offloading Frameworks
Technical ArticlesNov 1, 2020
Takamasa NAKASONE (VEOS Engineer)
AI Platform Division, NEC Corporation

This section describes an overview of SX-Aurora TSUBASA OS and its offloading feature.
SX-Aurora TSUBASA architecture, in short Aurora architecture in this document, is consisted of x86 server and PCIe cards composed of vector processers. This PCIe device is called VE, means Vector Engine. Meanwhile, the x86 server for SX-Aurora TSUBASA is called VH, means Vector host.
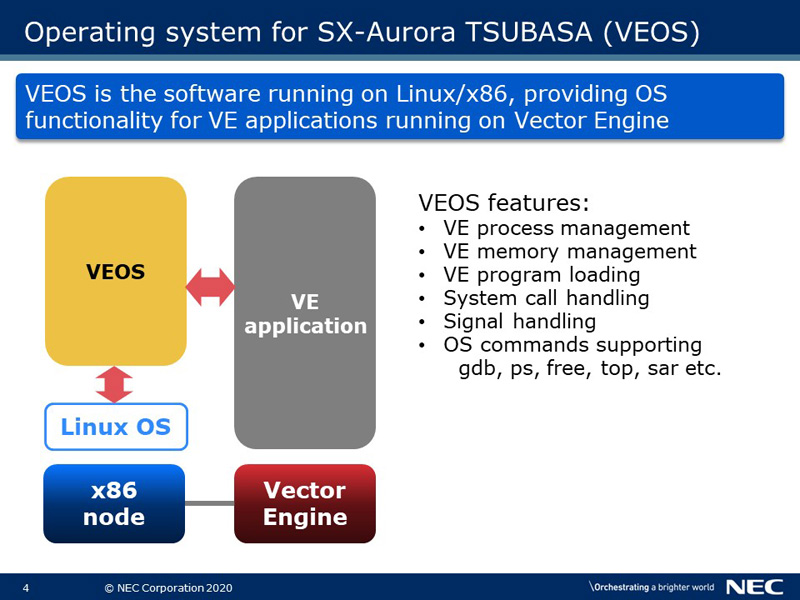
VEOS is an x86 application which provides OS functionalities for VE. For example, it loads a program to VE and manages processes and memory usage on VE. Because of these functionalities, entire user applications can run on VE. Besides, VEOS has two offloading features for VH and VE as described on the following slides.

This slide shows three programming models supported on SX-Aurora TSUBASA. The left one is the major programming model in which an entire user application runs on VE as described on the previous slide. The others are the offloading models in Aurora architecture.
The middle one is called VH Call in which a part of the program is offloaded to x86 side while the main program is running on VE side. It is helpful for VE applications to offload non-vectorizable operations.
On the other hand, Aurora provides an accelerator programming model such as GPGPU as shown in the right. It is called VEO, which means VE Offload. In this programming model, it is possible for an x86 application to call VE kernel function asynchronously.
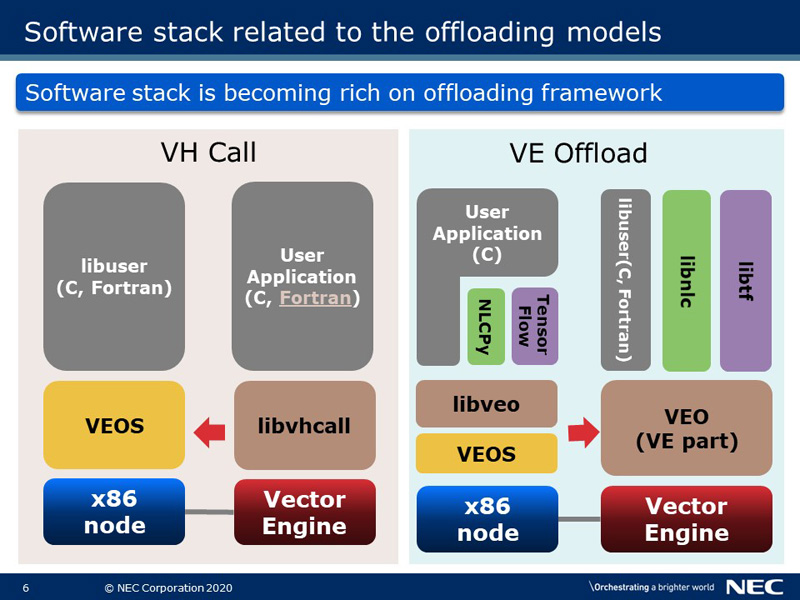
This slide shows the software stack on SX-Aurora TSUBASA using offloading programming. As shown on the left side, libvhcall provides VH Call API to VE Application. VE application can offload a part of some tasks as an x86 program to the x86 side. VH Call provides not only C APIs but also Fortran APIs in the recent update. On the other hand, libveo described at the right side provides VEO functionality through C API. It is used by user applications on the x86 side directly or through application frameworks such as NLCPy and TensorFlow. NLCPy is the Python bindings of numerical library collection developed by NEC. TensorFlow is an end-to-end open source platform for ML developed by Google. NEC's R&D team is working on porting TensorFlow to SX-Aurora TSUBASA. Programmers can develop kernel functions of applications (libuser) in C or Fortran. The VE Kernel function for these application and framework, libuser, libnlc or libtf, is working on the VE side.
By offloading the framework, the SX-Aurora TSUBASA software stack is becoming richer, for example, some Machine Learning applications can be run on SX-Aurora TSUBASA using TensorFlow.

This section describes basic usage of the two offloading features.
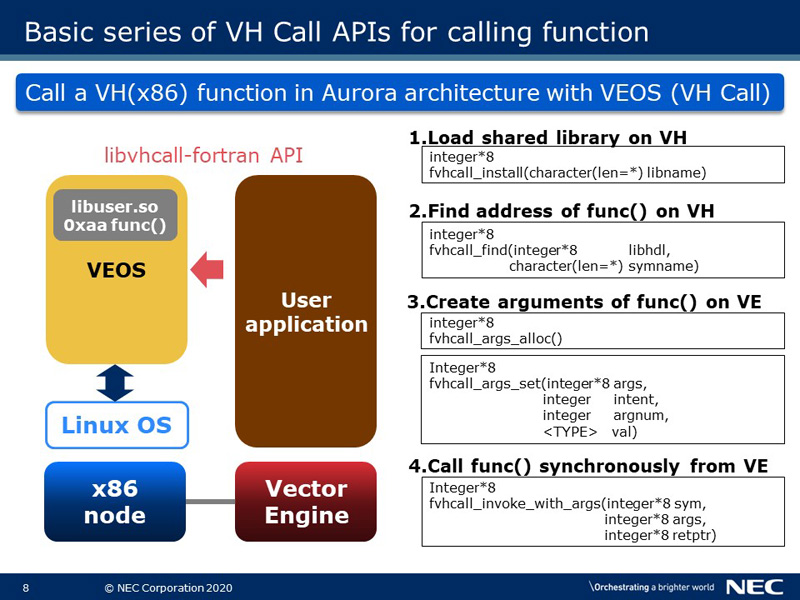
This slide shows the sequence of using the VH Call functionality. The offloaded part of a x86 code needs to be compiled into a shared library in advance. It is loaded to VH using the API, vhcall_install. Second, the address of the function in the loaded library is found by vhcall_find. Third, the argument needs to be prepared on the VE side. The API vhcall_args_alloc allocates a buffer for the argument and vhcall_args_set sets the value to it. Here, vhcall_args_set can set various basic types of C language. For example, you can set integer, double or pointer type to pass to VH function. Besides, pointer argument can be used as input or output buffer. Last of all, the VH function can be called synchronously using vhcall_invoke_with_args.
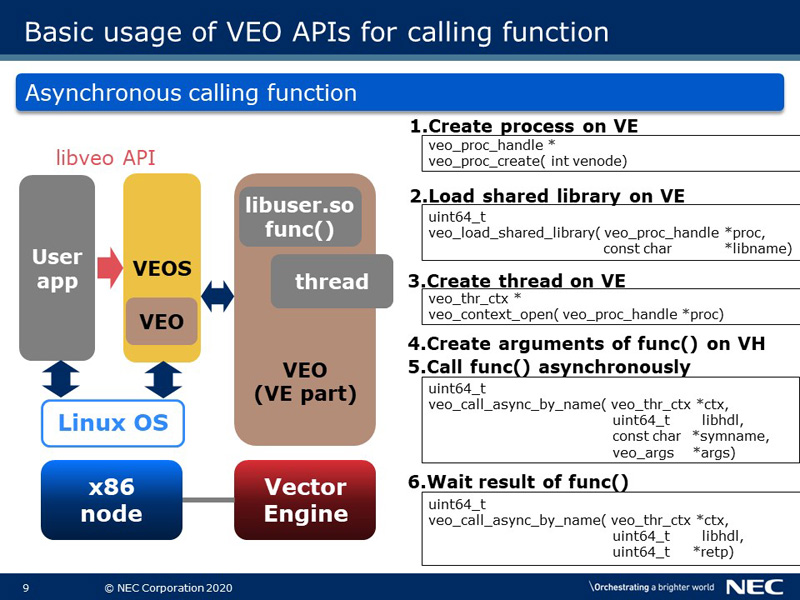
This slide shows the sequence of using VEO. There are two major differences from VH Calls in APIs. One of the differences is shown at the first and the third step. They are required to create a VE process or a thread to handle kernel functions because VEOS works on the x86 side and not on the VE side. The other is shown at the fifth and sixth step. They are for calling kernel functions and getting results. Because of the existence of the VE thread to handle the kernel function, it is possible to call VEO functions asynchronously.

This section describes an effective usage of VH Call and a recent update of VEO.

This slide describes an example of effective usage for VH Calls in an application. In the example above, the original Fortran code "fio.f" is divided into two parts, "VH part" and "VE part". "VH part" shows the code for offloading. The formatted IO operation in the code is one of the examples which is not vectorized and it is suitable for offloading to VH. Usually the formatted IO should be included in many of your applications. We have measured some cases using the sample code to evaluate the effectiveness of offloading. The first case is the one which compiled the sample program fio.f by nec-fortran and executed the entire program on VE. It takes too much time, 60 seconds, for the execution because the IO operation is not vectorized. The second case is the one for offloading in which the "VH part" is compiled with gfortran and the "VE part" is compiled with nec-fortran. The execution time of this case is 8.1 seconds which shows a performance improvement by about 7 times with offloading the non-vectorizable operation. For reference it takes 7.9 seconds when the original sample code "fio.f" is compiled by gfortran and executed on VH. This means the overhead of VH Call is about 0.2 seconds in this case.

We have released the new VEO implementation, AVEO, as a part of the latest update of VEOS at the end of September 2020. It is based on the implementation of AVEO developed by Dr. Erich Focht. AVEO shows a very high performance especially in latency and the calling function latency of AVEO is one tenth of the original VEO, and it also supports some features as follows:
- Multiple VE support creating VE processes on any node
- Debugger support which enables NEC debugger and GNU debugger to attach VE part and VH part in a single session
- Ftrace support on the VE kernel code
- Open MP is enabled as default. It can be changed by environment variable

This slide shows the performance of "heatequation" which is an application of NLCPy. The difference of the performance between VEO and AVEO as its implementation of NLCPy is described changing the size of input data. As shown in the graph, AVEO is more effective in performance compared to VEO especially when the size of the input data is small. This is because the influence of overhead for data transferring is more significant when the entire computing time on VE is small, that means latency of data transfer on AVEO is improved.
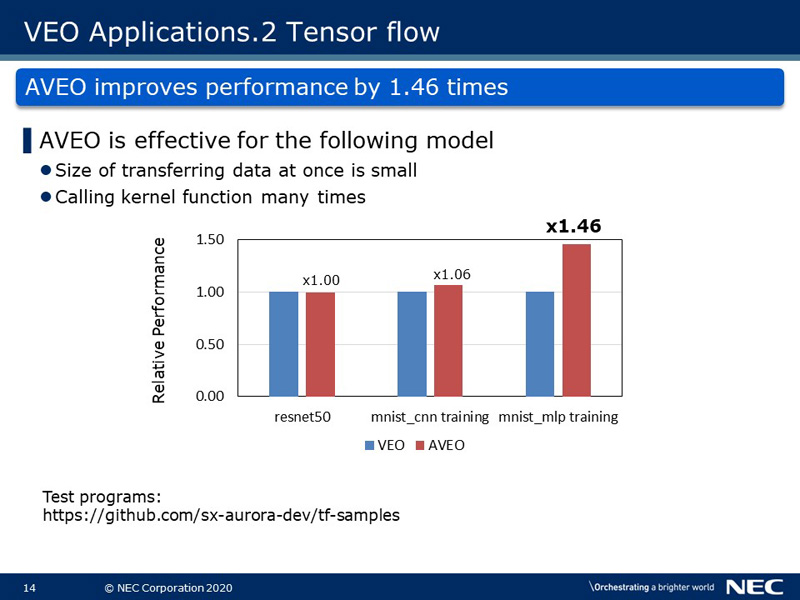
This slide shows the performance of some applications using TensorFlow comparing VEO vs AVEO as its implementation. Each red vertical bar shows the relative performance of AVEO when the VEO performance sets the base to one. As show in the graph, AVEO is more effective compared to VEO for the case of the multi layer perception "mnist_mlp training". It is an application for which the size of transferring data per one communication is small and the number of kernel function calls are large. This means that the performance of AVEO is better than VEO in view of latency of data transfer.
- Intel and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.
- NVIDIA and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries.
- Linux is a trademark or a registered trademark of Linus Torvalds in the U.S. and other countries.
- Proper nouns such as product names are registered trademarks or trademarks of individual manufacturers.